ADAPTIVE ADVERSARIAL CROSS-ENTROPY LOSS
FOR SHARPNESS-AWARE MINIMIZATION
Tanapat Ratchatorn and Masayuki Tanaka
Institute of Science Tokyo, Tokyo, Japan
IEEE International Conference on Image Processing (ICIP 2024)
[arXiv],
[GitHub]
Abstract
Recent advancements in learning algorithms have demonstrated that the sharpness of the loss surface is an effective measure for improving the generalization gap. Building upon this concept, Sharpness-Aware Minimization (SAM) was proposed to enhance model generalization and achieved state-of-the-art performance. SAM consists of two main steps, the weight perturbation step and the weight updating step. However, the perturbation in SAM is determined by only the gradient of the training loss, or the cross-entropy loss. As the model approaches saturation, this gradient becomes small and oscillates, leading to inconsistent perturbation directions and also has a chance of diminishing the gradient near the optimal stage. Our research introduces an innovative approach to further enhancing model generalization. We propose the Adaptive Adversarial Cross-Entropy (AACE) loss function to replace standard cross-entropy loss for SAM's perturbation. AACE loss and its gradient uniquely increase as the model nears convergence, ensuring consistent perturbation direction and addressing the gradient diminishing issue. Additionally, a novel perturbation-generating function utilizing AACE loss without normalization is proposed, enhancing the model's exploratory capabilities in near-optimum stages. Empirical testing confirms the effectiveness of AACE, with experiments demonstrating improved performance in image classification tasks using Wide ResNet and PyramidNet across various datasets.
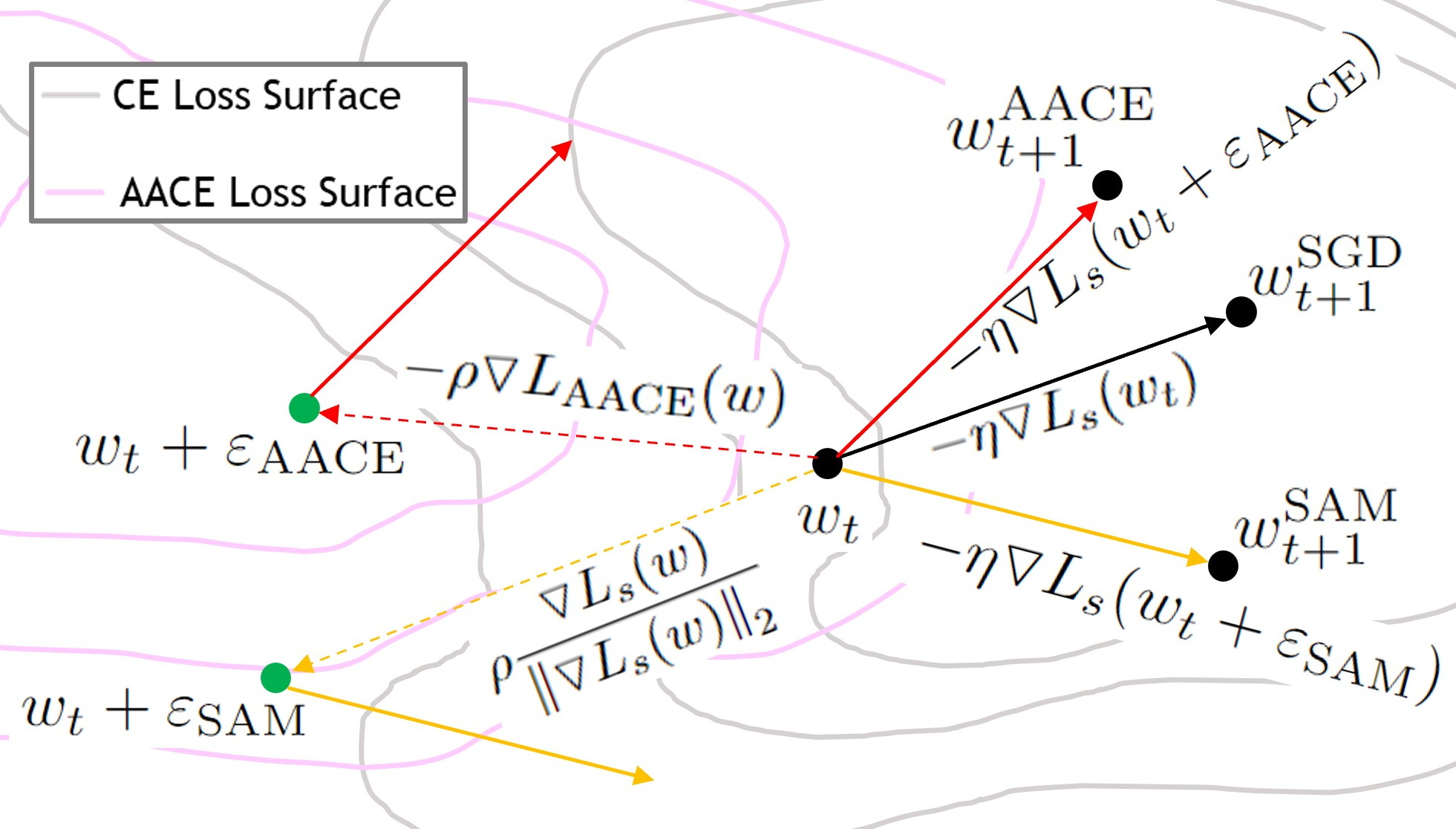
Method Overview
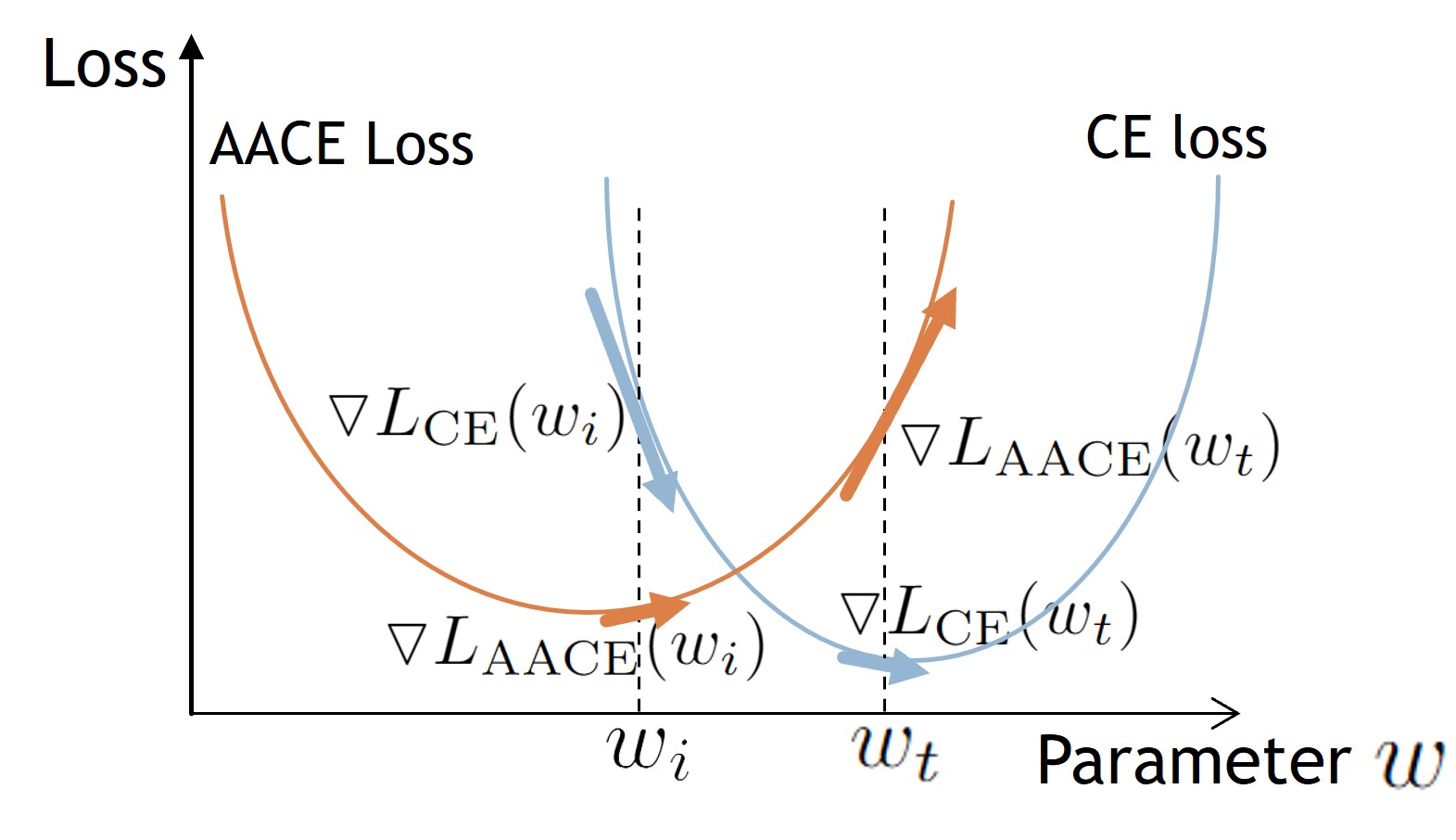
In this research, we found that, to find the worst-case parameters, SAM's perturbation depends on the normalized gradient of cross-entropy loss and a pre-defined constant radius of the neighborhood. Since at the nearly optimum stage, the gradient of cross-entropy loss is very small and fluctuates around the optimum point, this leads to the unstable direction of the perturbation. Another noticeable issue is that, at the nearly optimum stage, the magnitude of the gradient of cross-entropy loss becomes smaller and smaller and has a risk of being zero which could cause devising by zero problem.

Hence, we introduce an innovative method to address the challenges associated with SAM's perturbation step and satisfy the required properties of the perturbation. Our approach involves altering the loss function used for calculating the perturbation vector. Rather than relying on the cross-entropy loss, which diminishes as the model trained, we propose a novel loss function named Adaptive Adversarial Cross-Entropy (AACE). This new loss function is designed to increase magnitude as the model approaches convergence.
Empirical Results
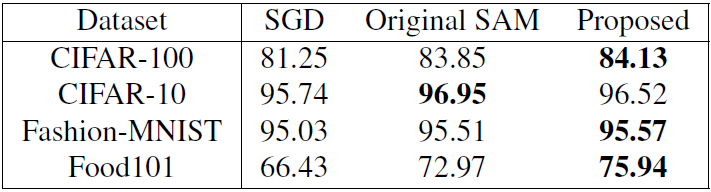
The empirical results confirmed our hypothesis on AACE characteristics and its improved generalizability over the original SAM.
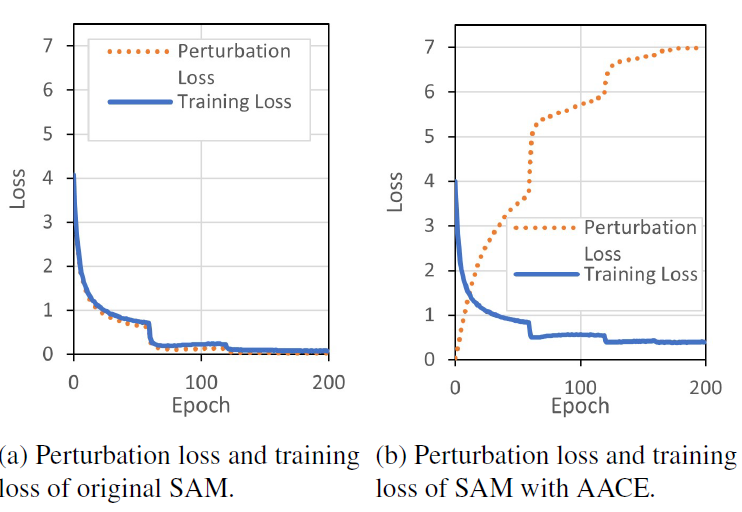

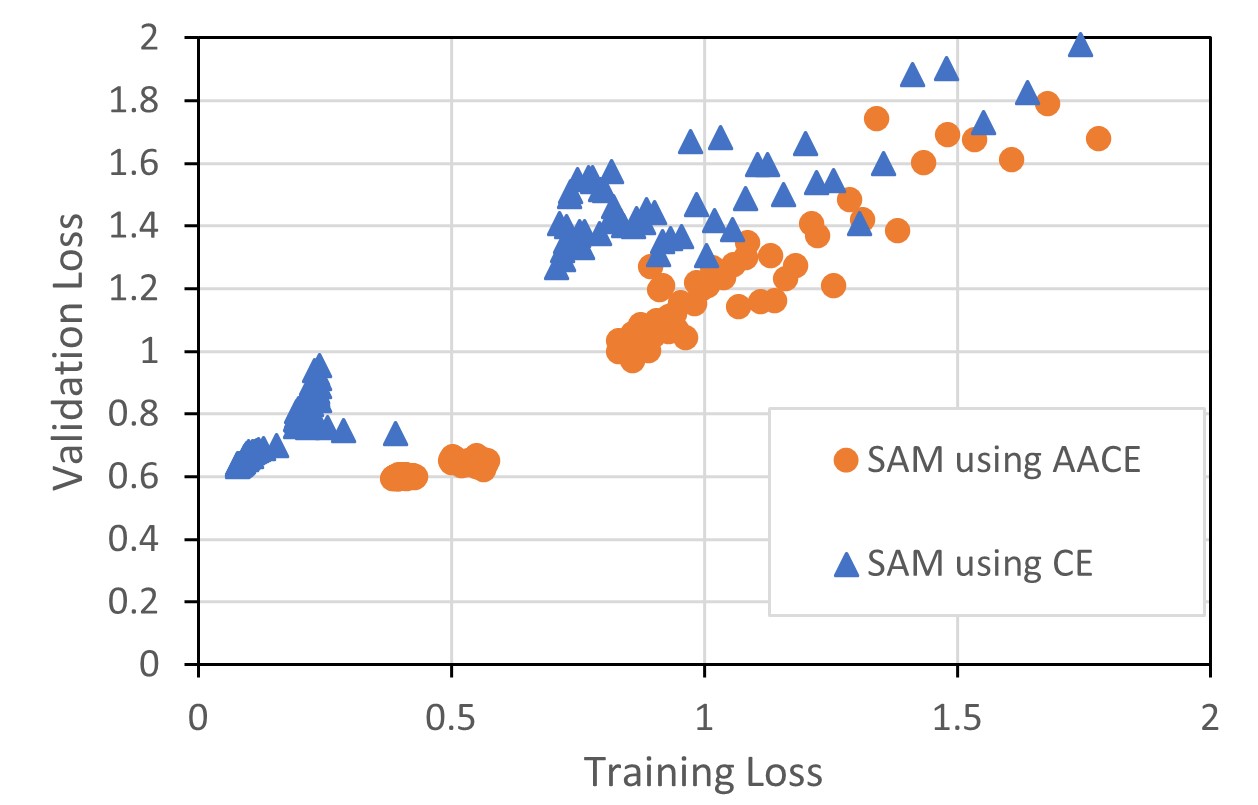
The experiments on Wide ResNet and PyramidNet models with CIFAR-100, CIFAR-10, Fashion-MNIST, and Food101 dataset show that our proposed method helps SAM to perform better for image classification tasks

Publication
Tanapat Ratchatorn and Masayuki Tanaka, “Adaptive Adversarial Cross-Entropy Loss for Sharpness-Aware Minimization”,
IEEE International Conference on Image Processing (ICIP), October, 2024.